

Role: Lead Product Designer & Facilitator
Context: Part of a £400m UK Government digital transformation programme
Focus: AI-assisted email triage and draft generation at scale. This project has been white labelled.
Government staff were manually reviewing, researching, and responding to thousands of complex public enquiries every week. Each response required interpreting technical policy documents, cross-referencing internal systems, and maintaining strict consistency with official guidance.
Response times were slow, quality varied by individual expertise, and the only available solution was more headcount.I led the design of an AI-assisted system to change that without removing human accountability from the process.
Staff were manually reviewing, researching, and responding to thousands of complex public enquiries every week. Each response required interpreting technical policy documents, cross-referencing internal systems, and maintaining strict consistency with official guidance. Response times were slow, quality varied by individual expertise, and the only available solution was more headcount.
Volume pressure: Thousands of emails per week with no viable path to keeping up without proportional staffing increases.
Policy complexity: Responses required navigating evolving technical and regulatory documentation that no individual could hold in full.
Consistency requirements: Tone, language, and accuracy had to align with official policy at all times, regardless of who was writing the response.
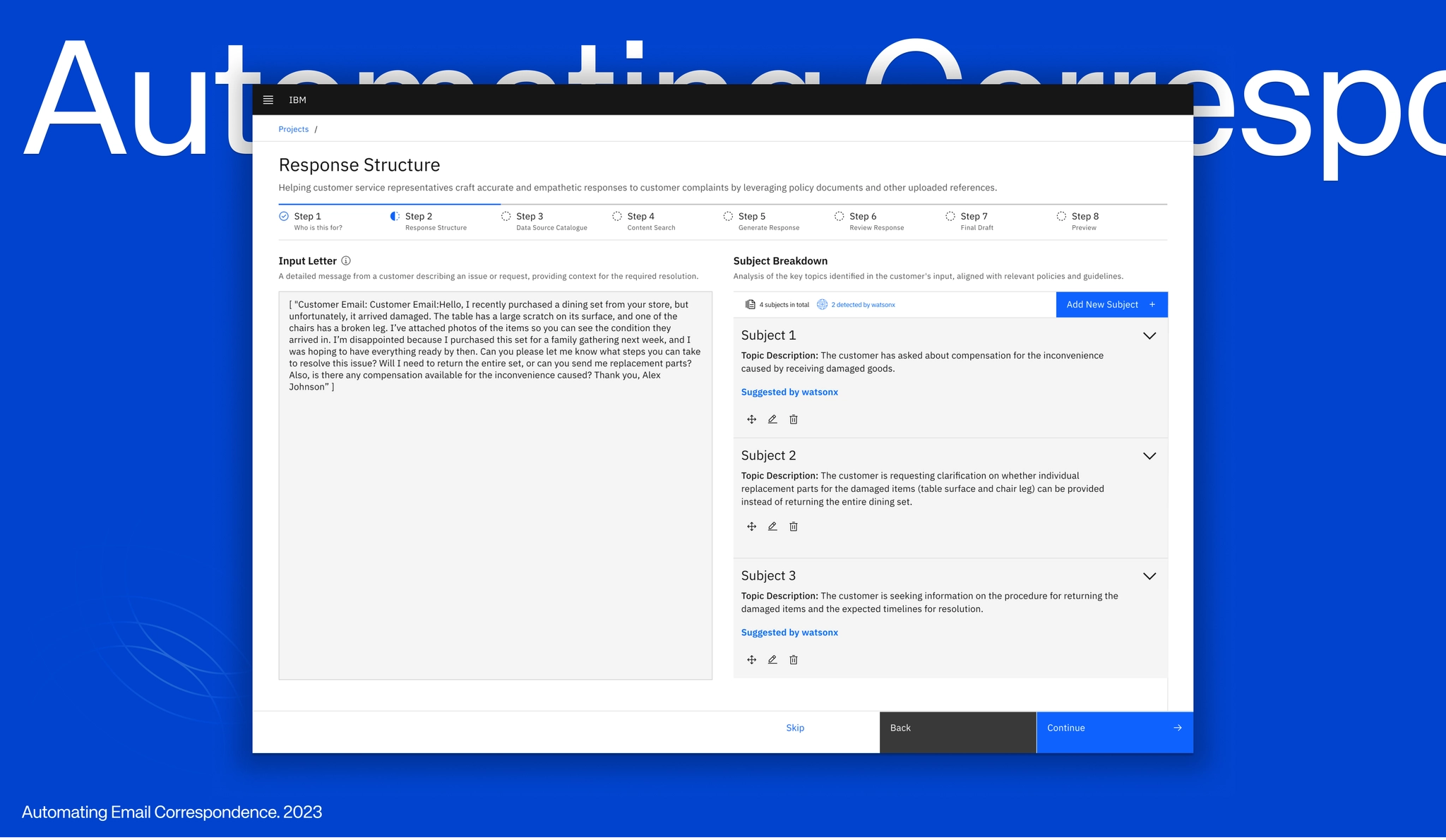
Staff needed to understand why a draft had been generated, and to see which documents it was grounded in, edit confidently without losing compliance alignment. Retaining clear ownership and transparency of every communication that left the organisation was essential.
I facilitated a two day work with the government team. We wanted to understand the current process and where failure and challenge occurred, the As-Is for email writing, policy understanding and how they would want AI to support their individual roles. Tone of voice and clarity of answer was a persistent theme throughout, attempting to answer: how do I keep the outputs consistent, governable and factual?

A system that augmented expertise without replacing it
End-to-end workflow
Ingest: Emails arrive and are automatically parsed through system
Classify: Intent and policy domain identified, queue prioritised
Retrieve: Relevant policy sections surfaced with confidence signals
Draft: RAG-grounded response generated with source traceability
Review & Send: Human approval required. Full edit control preserved

Intelligent email classification. Incoming emails were automatically categorised by intent and policy domain, enabling prioritisation and routing without manual triage. Staff saw organised queues rather than undifferentiated volume.
Retrieval-augmented draft generation. Users could upload policy documentation, technical guides, and reference links. The system retrieved relevant sections and used them to generate draft responses grounded in official sources. Each draft surfaced the referenced documents, relevant policy excerpts, and confidence indicators — making the reasoning traceable rather than opaque.
Human-in-the-loop review workflow. Drafts required explicit user approval before sending. The interface preserved full edit control, maintained clear separation between generated and human-written content, and captured feedback to improve future responses. The system augmented expertise. It did not replace it.
Measurable change across every dimension that mattered
Hours → Minutes: Response times for standard queries reduced dramatically
Volume scaled: Teams handled significantly increased volume without proportional staffing increases.
Consistency up: Policy alignment improved across all domains and staff members
The hardest design problems in AI are not about the model
Working at the scale and accountability requirements of government made one thing clear that is easy to obscure in faster-moving product contexts: accuracy and accountability are not the same constraint, and when they conflict, accountability wins. A system can produce correct outputs and still be unusable if the people responsible for those outputs cannot explain, defend, or take ownership of them.
This matters beyond government. It matters for any deployment of AI in contexts where decisions have consequences — where an output isn't just consumed but acted upon, attributed, potentially audited. The question 'is this correct?' is necessary but not sufficient. The operative question is 'can the person sending this stand behind it, and do they have everything they need to do so?' Those are design questions as much as model questions, and they require different answers. The system we built was structured around this distinction. Confidence indicators, inline citations, visible source attribution, mandatory human review before sending — these weren't features added for comfort. They were the conditions that made the system usable at all in this context. Strip any one of them and you don't have a slightly worse product; you have a product that the organisation cannot responsibly deploy.
