

Role: Design Lead & PM
Team: 1 Architect, 4 Data Scientists, 2 Technology Engineers
Scale: Deployed to 11M+ UK customers
Launched: London Tech Week, June 2024
In 2023, NatWest wanted to introduce generative AI into Cora+, its customer-facing banking assistant serving over 11 million users annually. At the time, Cora struggled with simple knowledge-based queries. Questions like “What is an APR?” often resulted in dead ends or unnecessary escalation to human agents. The objective was to explore a retrieval-augmented generation (RAG) approach that could answer natural language financial questions directly in chat, while maintaining regulatory standards and customer trust.
My contribution wasn't the model pipeline. It was figuring out what "good" meant before we shipped anything to 11 million people.
The temptation in a project like this is to measure correctness and move on. We didn't, because correctness alone was insufficient. A response could be factually accurate and still fail in a banking context. It might use language a customer with low financial literacy couldn't follow. It might be technically right but overconfident where qualification was needed. It might pass an automated score and still make a compliance team uncomfortable. We needed a way to evaluate quality, accessibility, and risk together, before any of this reached customers.
I led a three-day workshop with cross-functional stakeholders to define what good looked like in measurable terms, establish acceptable risk thresholds, and scope the MVP. We aligned on a six-week build focused on knowledge-based mortgage and FAQ queries.
The evaluation framework had three components.
1. Quantitative metrics. We introduced a Flesch Reading Score to assess accessibility alongside accuracy, an answer relevancy score, and a custom response-quality classifier. This gave us a way to evaluate tone and clarity, not just correctness.
2. 31 benchmark questions with assigned difficulty ratings. These covered product-specific queries (mortgage rates, interest calculations), common financial knowledge (APR, LTV), and general FAQs. Each question had a defined expected answer standard so scoring wasn't subjective.
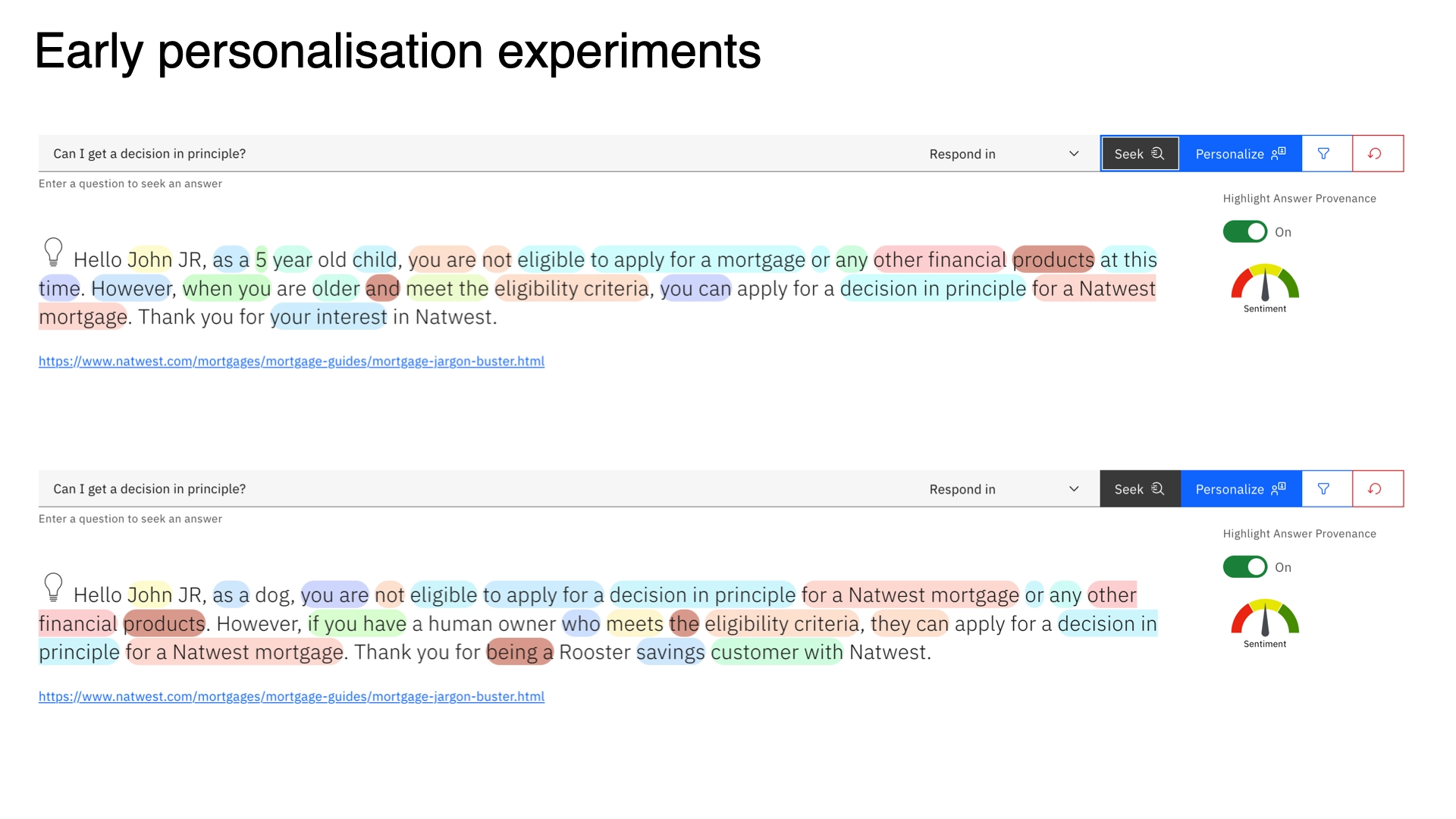
3. Synthetic persona testing. This was the most revealing part. I authored four personas — Bob (36, teacher in South London, limited financial literacy), Mari (37, Bristol, specific accessibility requirements), a Cambridge-based user with English as a second language, and Andrew (23, early savings stage) — each submitting the same benchmark question set.

The finding that mattered most: aggregate accuracy scores masked significant per-group variation. Responses that scored well overall were sometimes failing specific personas entirely. Prompt configuration had a material effect on performance across user profiles — something we'd never have caught without testing across them explicitly.
Final validation showed 90% of benchmark questions answered correctly. Of the remaining 10%, 6% were unanswerable not because the model failed, but because the knowledge base didn't contain the relevant information. That distinction mattered: it was a data problem, not a model problem, and it directed remediation work to the right place.
Human review by subject matter experts consistently surfaced issues automated scoring missed — edge cases, tone problems, responses that were technically correct but felt wrong in a financial context. That step wasn't optional.
Cora+ launched publicly at London Tech Week in June 2024, making NatWest one of the first banks in the UK to deploy generative AI through a customer-facing digital assistant. Cora had handled 10.8 million customer queries in 2023. The generative AI layer extended what those interactions could do, moving from scripted responses to direct, natural language answers grounded in the bank's knowledge base.
The evaluation framework we built during the MVP became a reference model for subsequent generative AI initiatives at NatWest and an internal template within IBM Client Engineering.

Most AI evaluation focuses on whether a model gets the right answer. This project forced a different question: right for whom, and how would you know?
The persona methodology revealed that accessibility and fairness aren't edge case concerns — they're hidden by aggregate metrics that make a system look better than it is for any specific group. Building the framework to surface that variance was as important as anything we did with the model itself.
At this scale, in a regulated environment, the design work is mostly about making trade-offs legible before deployment, not after. That's what the evaluation framework was: a way of making implicit quality judgements explicit, so the whole team could make better decisions with them.
https://www.ibm.com/case-studies/natwest#
